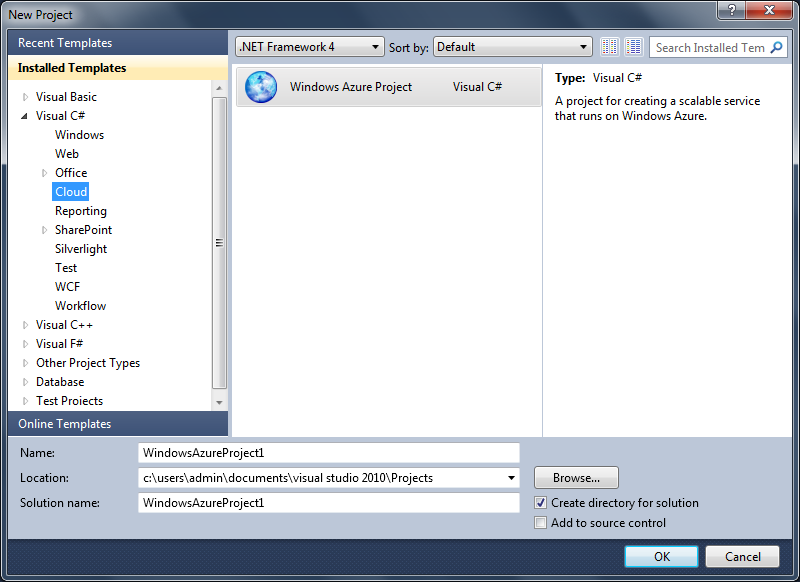
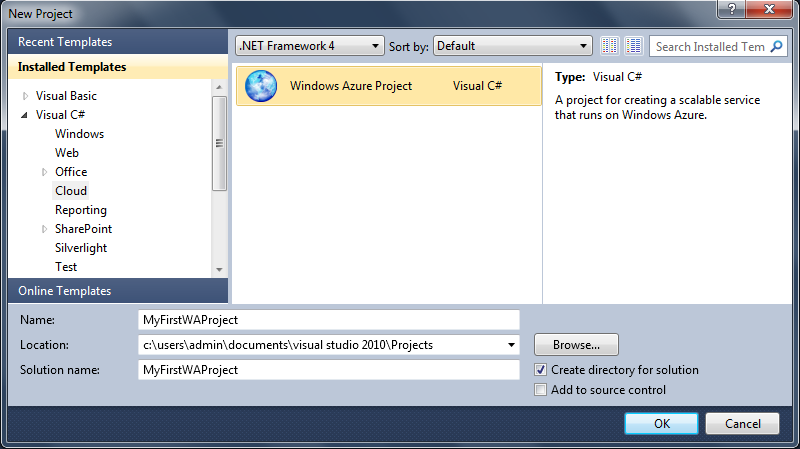
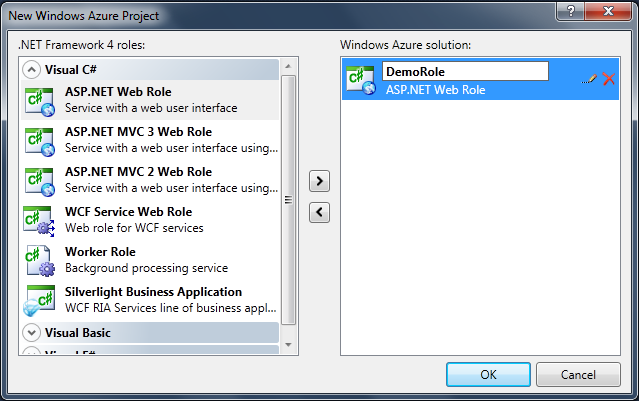
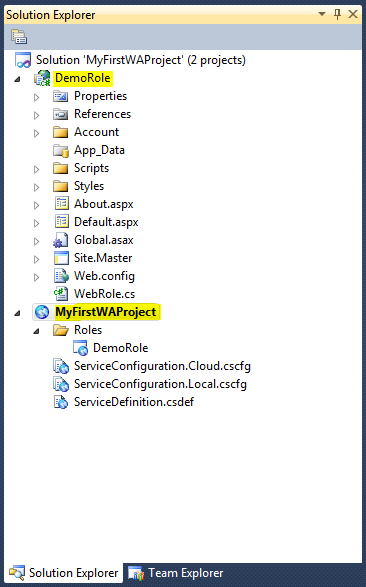
AWS RDS Proxy is a fully managed service designed to optimize database connection management, improve performance, and reduce latency in dynamic, highly-scalable environments like serverless applications and microservices architectures. While it brings many advantages, particularly in managing high volumes of database connections, there are some limitations and costs that may affect its viability in certain use cases.
This blog will cover the key benefits of RDS Proxy, the problems it solves, the concept of connection multiplexing, and highlight some significant limitations. We will also explore alternatives available in the market that could serve as a better fit in specific environments.
What problem does AWS RDS Proxy solve?
1) Connection Management in Serverless and Dynamic Environments.
Relational databases like MySQL, PostgreSQL, and MariaDB have inherent limits on the number of simultaneous connections they can handle. Serverless applications (e.g., AWS Lambda) or auto-scaling services can generate a high number of short-lived connections, which can overwhelm the database and lead to performance degradation.
Solution: Connection Pooling and Multiplexing
AWS RDS Proxy creates a pool of database connections that are reused across multiple application instances. It implements connection multiplexing, where multiple application requests share fewer database connections. This reduces overhead, prevents connection storms, and allows applications to scale more efficiently without burdening the database.
Additionally, multiplexing helps consolidate idle connections, preventing them from occupying database resources, which is critical for high-traffic applications with unpredictable workloads.
2) Reducing Latency in Serverless Architectures
In serverless environments, functions such as AWS Lambda often open new database connections every time they execute. Opening and closing database connections can introduce significant latency, which affects application performance.
Solution: Persistent Connections
RDS Proxy keeps persistent connections to the database, so serverless functions can reuse existing connections rather than repeatedly establishing new ones. This improves performance by reducing the latency associated with connection setup and teardown, especially in bursty traffic patterns.
What are the key limitations of AWS RDS Proxy?
While AWS RDS Proxy solves many connection management problems, it has some significant limitations that affect its flexibility and cost-effectiveness in certain scenarios.
1) VPC Endpoints and Data Transfer Costs
By default, RDS Proxy has a fixed base cost as AWS manages the dedicated infrastructure and scaling for RDS Proxy. This includes a single VPC endpoint setup for the DB writer endpoint. However, this does not cover data transfer costs, which apply separately for traffic flowing through the endpoint. If additional custom reader endpoints are needed, they incur extra charges (for every endpoint) as it may require additional compute and networking resources.
Cost Implications: When you set up custom endpoints for read traffic, especially in read-heavy workloads, these VPC endpoint data transfer costs can quickly add up, making RDS Proxy expensive for read scaling. In some cases, the cost becomes so high that it may be more economical to simply run additional read replicas instead of relying on RDS Proxy. Cross-AZ data transfer can also contribute to data transfer costs. Data transfer within the same Availability Zone (AZ) is free, while transfer between different AZs incurs charges. In a multi-AZ setup, ensuring that all traffic between the RDS Proxy and the RDS instance remains within the same AZ can be challenging in high availability setup.
2) Custom Reader Endpoint Limitations: No Granular Control
RDS Proxy enables the creation of custom reader endpoints for distributing read traffic, but it lacks granular control over reader selection. When using custom reader endpoints, you cannot specify which read replicas to include behind the proxy—RDS Proxy automatically distributes traffic across all available readers. This can be a drawback in scenarios where certain replicas are optimized for specific tasks, such as analytics, making it difficult to direct queries to the most suitable instance.
3) Noticeable Latency in changing database clusters attached to the Proxy
RDS Proxy does not handle cluster changes seamlessly, leading to noticeable latency when transferring active connections from one cluster to another, such as during a database upgrade or migration using blue/green deployments. Failovers, read replica promotions, and scaling events can introduce delays ranging from seconds to minutes, as RDS Proxy must detect changes, rebalance connections, and handle DNS propagation. Additionally, connection draining during instance removal can further impact latency.
Workaround: To mitigate these issues, a more effective approach is to set up a new proxy for the new cluster and manage the transition using Route 53 Weighted CNAMEs, allowing for a gradual shift of traffic while minimizing disruptions. This strategy ensures a smoother migration compared to reassigning an existing proxy, which would otherwise introduce additional failover delays. Implementing retry logic and reducing DNS TTL in your application can further enhance failover efficiency.
4) RDS Proxy Costs Are On-Demand Only
Unlike RDS instances, which can benefit from Reserved Instance pricing to lower costs over a long-term commitment, RDS Proxy is only available with on-demand pricing. This can make it more expensive in the long run, especially for users with predictable, long-term workloads.
AWS charges for RDS Proxy based on the number of vCPUs in your underlying database cluster, billing per vCPU per hour. Since RDS Proxy manages and optimizes connections to your database, its pricing is directly tied to the compute capacity of the database it supports. This means that even if your application isn’t actively using RDS Proxy, you are still billed based on the database’s vCPU count. Because of this pricing model, costs can scale up significantly in high-performance environments with large database clusters.
What are the alternatives to AWS RDS Proxy?
Given the limitations in cost and flexibility, it’s important to also consider alternative solutions that may better meet your needs.
1) PgBouncer – It is a lightweight connection pooling solution for PostgreSQL.
Advantages: (a) Supports for session, transaction, and statement pooling, (b) Open-source and highly configurable for advanced use cases, (c) Low overhead, ideal for high-throughput environments.
Limitations: (a) Requires manual deployment and management, (b) Limited to PostgreSQL databases.
2) HAProxy – It is an open-source proxy server and load balancer designed for managing database traffic.
Advantages: (a) Can load balance both application and database traffic, (b) Flexible configuration options to suit complex workloads.
Limitations: (a) Requires more setup and maintenance than AWS RDS Proxy, (b) Not as tightly integrated with AWS services.
3) ProxySQL – It is a high-performance, SQL-aware proxy built for MySQL and MariaDB.
Advantages: (a) Supports advanced routing, query caching, and load balancing, (b) Highly customizable to optimize database performance.
Limitations: (a) Limited to MySQL and MariaDB, (b) More complex setup and maintenance compared to RDS Proxy.
4) Amazon Aurora Endpoints – Amazon Aurora offers built-in read and write endpoints to handle traffic distribution between the writer and read replicas.
Advantages: (a) Automatically distributes read traffic across both fixed and autoscaled short-lived read replicas and sometimes selectively chosen replicas while excluding others., (b) Fully integrated with the AWS ecosystem, optimized for Aurora MySQL and PostgreSQL.
Limitations: (a) Only available for Amazon Aurora (MySQL and PostgreSQL-compatible).
Conclusion
AWS RDS Proxy is a robust solution for managing database connections, particularly in dynamic environments such as serverless applications and microservices. It provides key advantages, including connection pooling, multiplexing, and reduced latency, making it a valuable tool for handling high-throughput workloads. However, it also has limitations, such as high VPC endpoint data transfer costs, limited control over read replica selection, and the lack of Reserved Instance pricing.
For read-heavy workloads or predictable, long-term usage, RDS Proxy’s costs can become a concern, particularly when considering custom reader endpoint fees and data transfer fees. In such cases, alternatives like PgBouncer, ProxySQL, or simply scaling with additional read replicas may be more cost-effective. Additionally, using Route 53 weighted CNAMEs to manage cluster transitions during upgrades can help overcome some of RDS Proxy’s limitations.
Ultimately, deciding whether to use AWS RDS Proxy requires a careful assessment of your application’s traffic patterns, read/write ratios, and cost constraints. While its seamless AWS integration and automated connection management can justify the expense in certain scenarios, open-source or alternative AWS solutions may offer greater flexibility and cost efficiency in others.